# Abstract
60,000,000 参数
650,000 神经元
五层卷积层 删除任何一层都会导致性能下降
三层全连接层 softmax 1,000
全连接层加入 Dropout 层防止过拟合 (effective)
ImageNet 包含超过 1500 万张标记的高分辨率图像,涵盖 22000 多个类别。
CNN 相较 FNN (standard feedforward neural networks) 参数少,效果相差不大,易训练
训练了 90epoch
CNN 需要指定输入维度,降低分辨率至 256x256 (较短一侧长度缩至 256,保留中间部分)
同时在每个像素中都减去训练集对应像素均值 (凸显差异)
# ReLU Nonlinearity
non-saturating
采用 ReLU 相较 Sigmoid 和 Tanh 速度快几倍
ReLU 更易训练,加速收敛
# Training on Multiple GPUs
多卡训练以训练大网络
gpu 只在某些层进行通信分组卷积,优化其通信量与计算量占比
# Local Response Normalization(x)
有助于泛化
更类似于亮度归一化 (由于没有减去平均值,因而非对比度归一化)
归一化的意义是什么 (?)
LRN 的直观解释就是,在第 i 个特征图上的 (x,y) 处的神经元的值,通过其邻近的 n 个特征图上,同一位置的值平方和的相关运算,最后得到的值作为该特征图上,对应位置的新值。
可想而知,其计算量不小!后面的研究者也发现,LRN 并无实际作用,反而增加不少的计算量,因此一般都不再使用。
摘自知乎
# Overlapping Pooling
Pooling 重叠,重复利用某些像素
更难过拟合
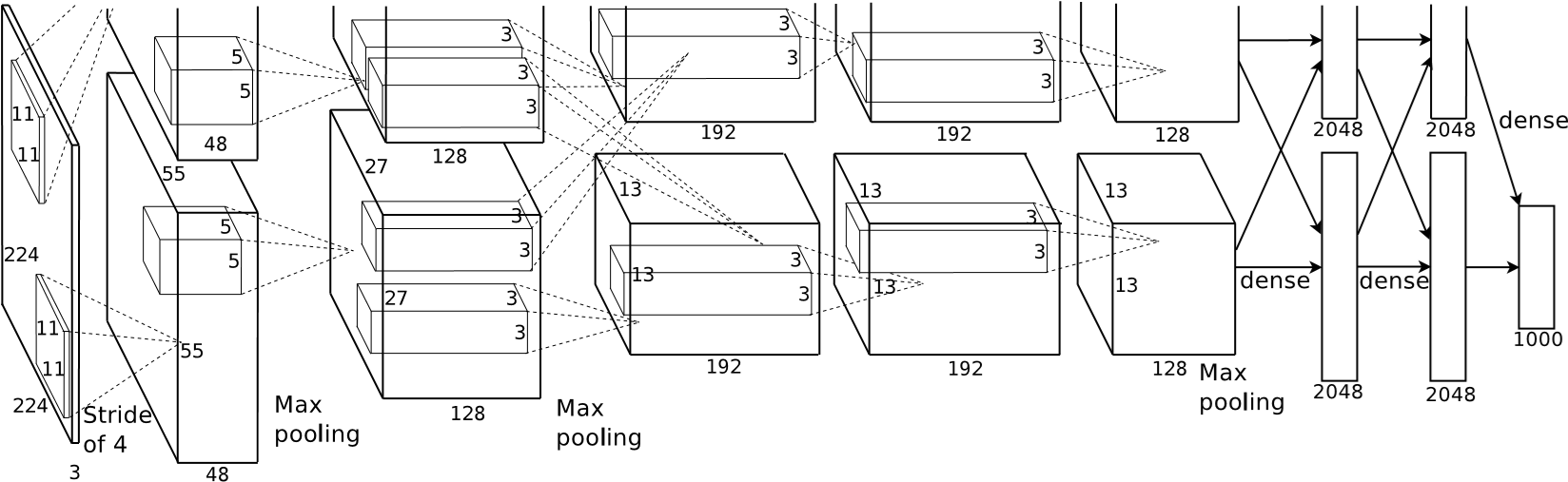
# Overall Architecture
网络结构
The first convolutional layer filters the 224×224×3 input image with 96 kernels of size 11×11×3 with a stride of 4 pixels (this is the distance between the receptive field centers of neighboring The second convolutional layer takes as input the (response-normalized and pooled) output of the first convolutional layer and filters it with 256 kernels of size 5 × 5 × 48. The third, fourth, and fifth convolutional layers are connected to one another without any intervening pooling or normalization layers. The third convolutional layer has 384 kernels of size 3 × 3 × 256 connected to the (normalized, pooled) outputs of the second convolutional layer. The fourth convolutional layer has 384 kernels of size 3 × 3 × 192 , and the fifth convolutional layer has 256 kernels of size 3 × 3 × 192. The fully-connected layers have 4096 neurons each.
# Reducing Overfitting
-
Data Augmentation 数据增强
~加大数据集- image translations and horizontal reflections.
训练集规模扩大 2048 倍 (?)
horizontal reflections 水平翻转
这边的操作就是先将原图水平翻转,之后在原图及翻转后的图中取样 (四角和中间) 227x227 像素
不过感觉这样其实也增强不了多少数据- 改变 RGB 通道强度 PCA (解释有点不知所云,是不是与原图相近 (RGB 通道强度改变少的) 的保留更多?)
- image translations and horizontal reflections.
-
Dropout 层
- probability=0.5 (? 太大了)
- 在前两个全连接层中使用
- 导致收敛时间增大 (~2 倍),但是不容易过拟合
验证集错误率在当前学习率停止改善时,学习率除以 10。
i 是迭代数,v 是 momentum,ε 是学习率, 是目标函数对 w 在 wi 上的第 i 批微分 Di 的平均。
# 思考
训练大网络要防止过拟合,Dropout 层不可或缺,训练集的大小很重要,数据增强很重要。
ReLU 替代 Sigmoid、Tanh 加速收敛,减少耗时。
在之前写的 CNN 十分类网络中再考虑将数据集进行增强,且调大 Dropout 的 probability。